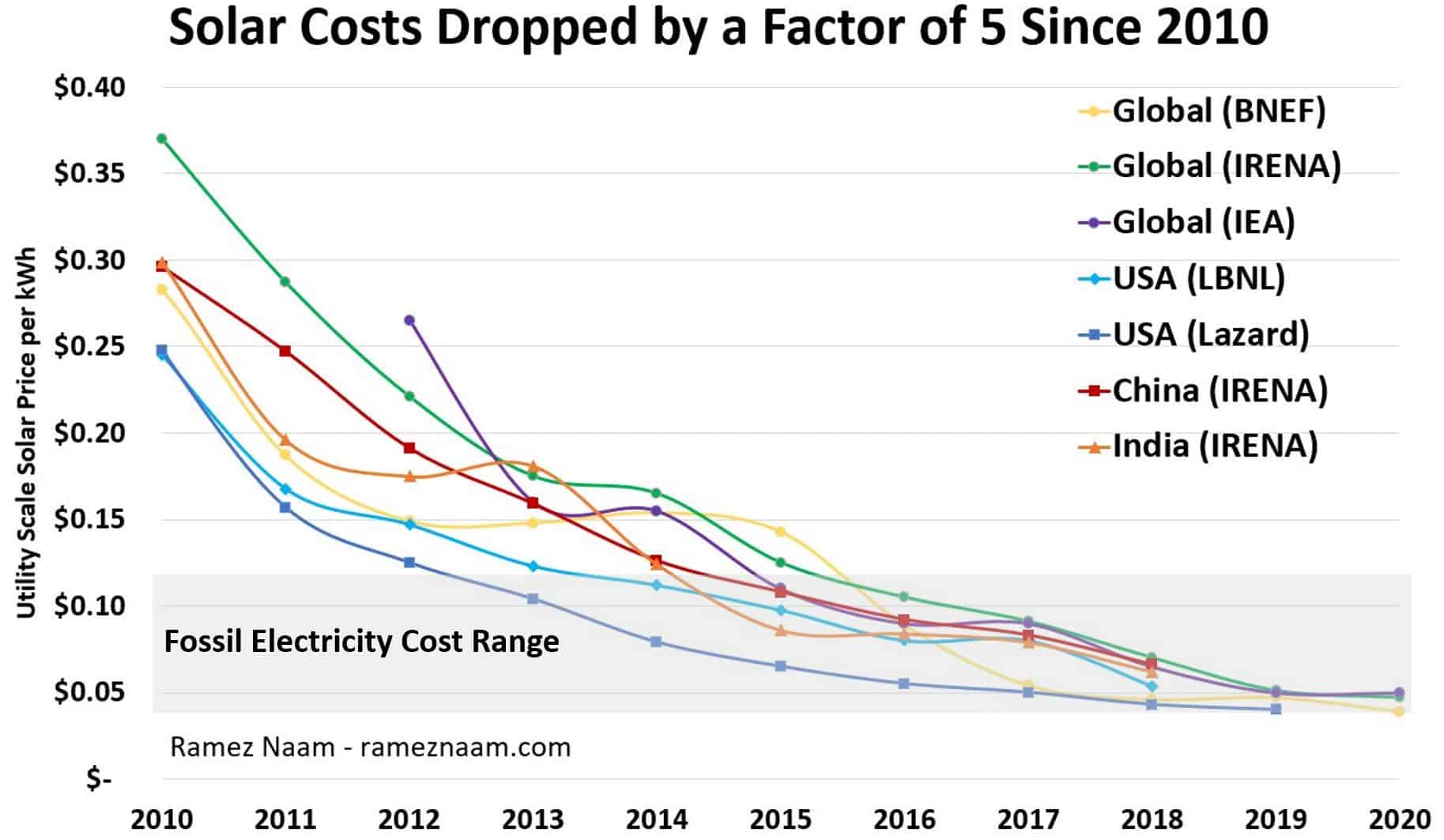
Solar’s Future is Insanely Cheap (2020)
14 May, 2020
This is part 1 of a series where I’ll look at the future costs of clean energy and mobility technologies. This is a refresh of and expansion of my 2015 series on the future of solar, wind, batteries, and electric vehicles. Tune back in for…
R e a d M o r e
The Third Phase of Clean Energy Will Be the Most Disruptive Yet
2 Apr, 2019
Building new solar, wind, and storage is about to be cheaper than operating existing coal and gas power plants. That will change everything. When the history of how humanity turned the corner on climate change is written, we’ll look back and see that clean energy –…
R e a d M o r eClean Technology is Disrupting Fossil Fuels Faster Than Ever
18 Sep, 2018
The best news in the global fight against climate change is the pace at which clean technology is advancing. That technology is on a path to disrupt fossil fuel electricity, oil, the automotive industry as solar and wind power, batteries, self-driving cars used by the…
R e a d M o r eYes, Blockchain Can Help Us Solve Climate Change – Why I Joined Nori
10 Sep, 2018
Over the last two years, as both an angel investor and a public speaker on energy and climate, I’ve looked at least a few dozen startups and proposals on how to use blockchain or new crypto coins in energy or climate. I’ve passed on all of…
R e a d M o r eSolar doesn’t need a “breakthrough”. It’s a breakthrough on it’s own.
4 Jan, 2018
Yesterday, Tyler Cowan, who I’m a major fan of, wrote a piece for Bloomberg View arguing that solar needs more R&D for a true green energy breakthrough. This logic mirrors that of Bill Gates, the Breakthrough Institute, and others who, over the years, have argued…
R e a d M o r eClean Energy Disruption – Video from South Africa
13 Nov, 2017
I spoke at the SingularityU South Africa Summit earlier this year, about the way that solar, wind, storage, and electric vehicles are disrupting the $6 Trillion a year energy industry worldwide, and the opportunities for South Africa and the whole of the African continent. It was…
R e a d M o r eDon’t Let the Terrorists Win – White Supremacy Edition
14 Aug, 2017
“Don’t let the terrorists win.” We said that a lot after 9/11, and have for the last 16 years. As air travel became absurdly cumbersome, as civil liberties were eroded, as people were arbitrarily blacklisted or detained without room for appeal – we said the…
R e a d M o r eWhy Trump Won’t be Impeached Any Time Soon
16 Jun, 2017
I see any impeachment of Trump before 2019 as extremely unlikely. Here’s why. First, for context, I believe the GOP as a party would be better off with a swift impeachment and resignation than a protracted scandal. Every week this remains in the news, their…
R e a d M o r eHealthcare Improvements Republicans Could Make
25 Mar, 2017
Here are some things the GOP could productively do on healthcare, that have little or nothing to do with repealing the ACA: 1. Price transparency and consistency. Require all providers (hospitals, doctors, etc..) to clearly publish their prices by service and by diagnosis in advance,…
R e a d M o r eOur Future Cyborg Brains: My Keynote at XTech 2017
22 Mar, 2017
I had a fantastic time keynoting the XTech Experiential Technology conference last week. Thanks very much Zack Lynch and Adam Gazzaley for the invitation. I talked about the science that inspired my Nexus novels, and what it might mean for society. You can check out…
R e a d M o r e